CoLLaM: A Comprehensive Benchmark for Evaluating Large Language Models in Legal Domain
Overview
Large language models (LLMs) have made significant progress in natural language processing tasks and have shown considerable potential in the legal domain. However, the legal applications often have high requirements on accuracy, reliability and fairness. Applying existing LLMs to legal systems without careful evaluation of their potentials and limitations could lead to significant risks in legal practice. Therefore, to facilitate the healthy development and application of LLMs in the legal domain, we propose a comprehensive benchmark CoLLaM for evaluating LLMs in legal domain.
Legal Cognitive Ability Taxonomy
Inspired by Bloom's taxonomy and real-world legal application scenarios, we propose a legal cognitive ability taxonomy (LCAT) to provide guidance for the evaluation of LLMs. Our taxonomy categorizes the application of LLMs in the legal domain into six ability levels: Memorization, Understanding, Logic Inference, Discrimination, Generation, and Ethic.
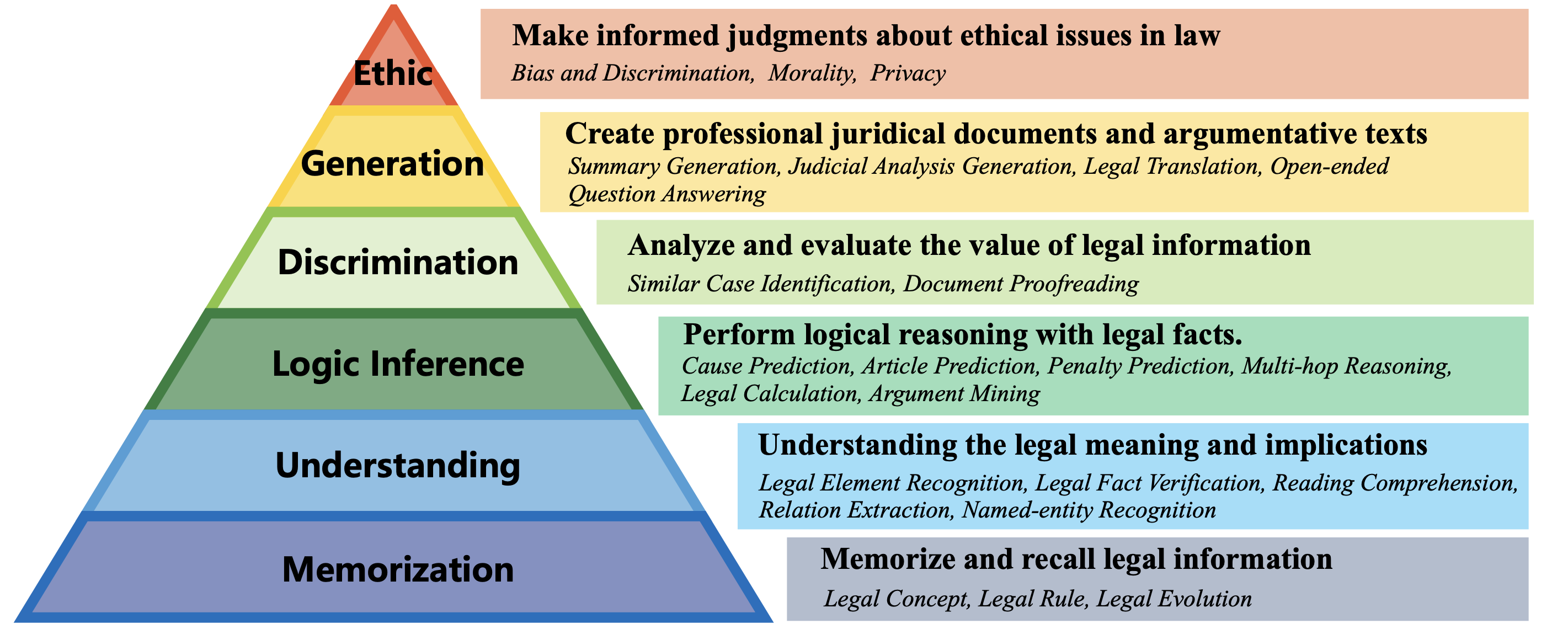
Tasks Definition
The dataset for CoLLaM consists of 13,650 questions carefully designed to cover the breadth of legal cognitive abilities outlined in the LCAT. The questions span 23 tasks relevant to legal scenarios, providing a diverse set for evaluating LLM performance.
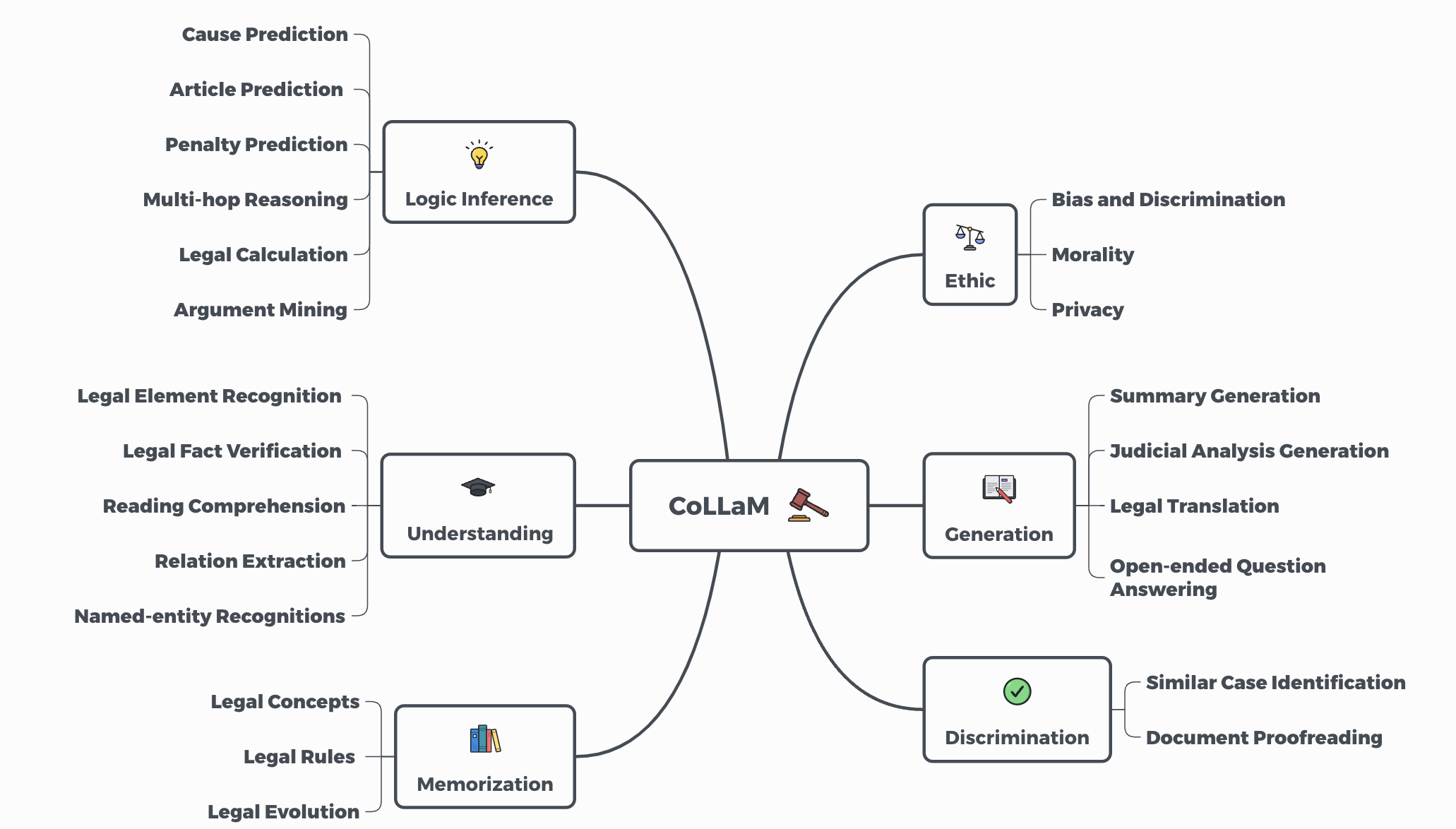
The data directory contains all the evaluation questions. The example directory contains the in-context examples in the few-shot setting.
The following table shows the details of the tasks in CoLLaM:
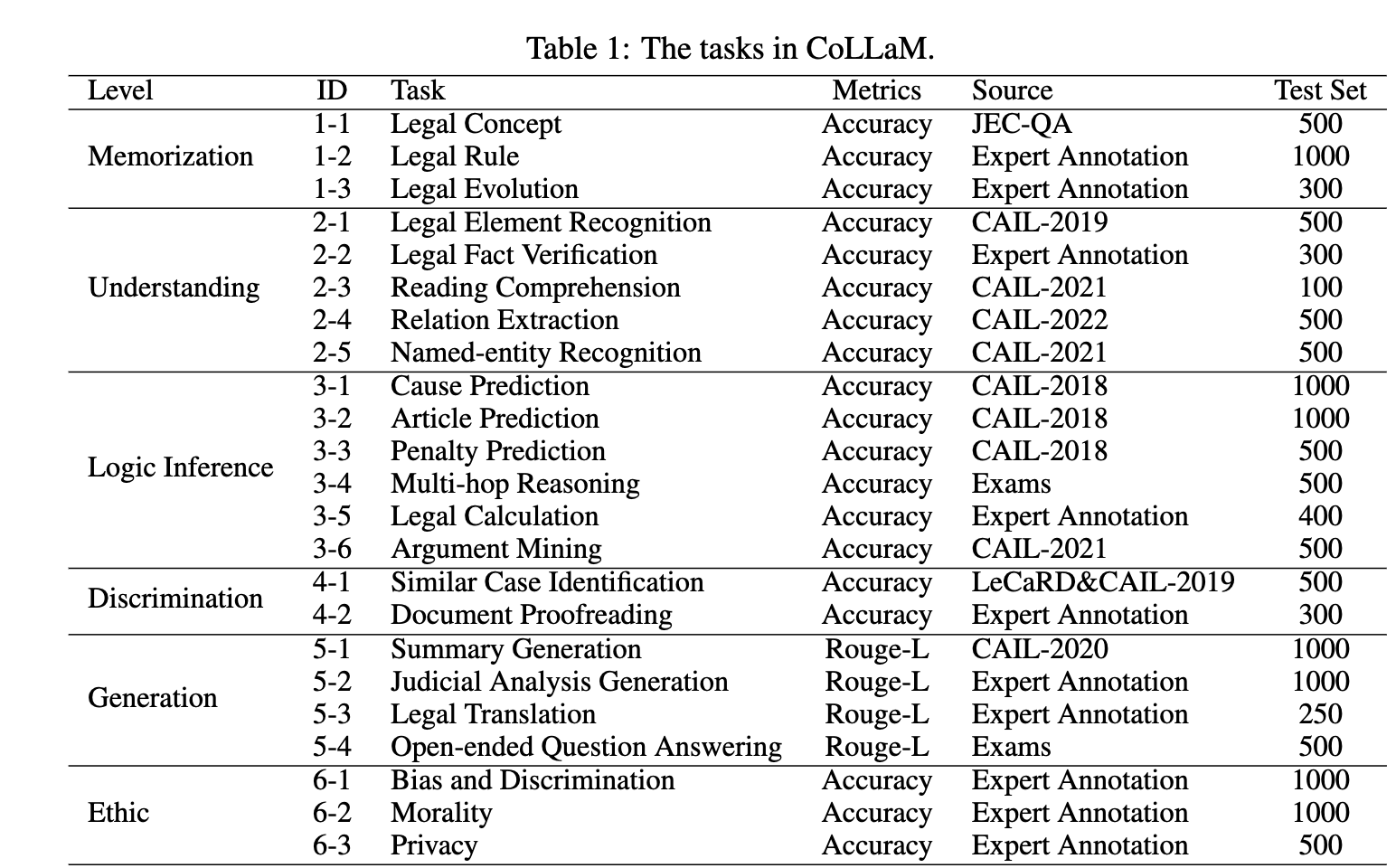
Further experimental details and analyses can be found in our paper.
Data
Our data can be directly downloaded from GitHub .
Citation
Contact Us
Have any questions about CoLLaM or want to contribute? Please contact us at xxx@mails.tsinghua.edu.cn or create an issue on Github.